經過這長時間的警戒之後,人心似乎變硬了,聽到呻吟大家照常行走、過日子,好似那是人類的自然語言。
-- <瘟疫>,卡繆著,嚴慧瑩譯
到了 8/19,開賽的氣氛逐漸逼近。但是 gen5/gen6 世代沒有什麼建樹。主要是,至此為止一直都只有使用交叉驗證機制,也就是,同一份資料集,透過切分 K 次、訓練 K 次的方式,其實並沒有一個資料集合是真正意義上模型完全沒見過的。所以這個階段補上了一個參數,傳入模型訓練時從來沒見過的資料集,這個資料集在過去的系列文當中被我稱為驗證集,也在後來的觀察與實驗之中佔了很重要的地位。
還有昨天提到的,一度移除的第四個優化項,加回到驗證階段的計算,因為我還是希望可以看到,就算不針對這個項優化,也能看到這個模型不只是有些策略的概念,而是對於遊戲的規則也有概念。具體說,這個項目是,將 ones 向量減去合法性向量,得到非法性向量之後,與策略做簡單的乘績。理想上,一個普通人類只要學會了遊戲規則,這個項的數值就一定是 0。
另外在 gen5,有別於其他世代的紀錄往往只有一份總結的 markdown 檔,當初 gen5 原本想將驗證遊玩的實踐常態化,因此加入了一個其他地方也沒有的 csv 檔紀錄大量的對戰組合。當然,因為對局很耗時的緣故,這個的局數並不項其他驗證遊玩一樣超過一百局,而是印象中每組對戰 20~40 局遊戲。但是,小局數對戰,就又會有蠻大的誤差範圍。較高的勝率未必代表它真的較強,但可以作為參考就是。當時得到兩個結論
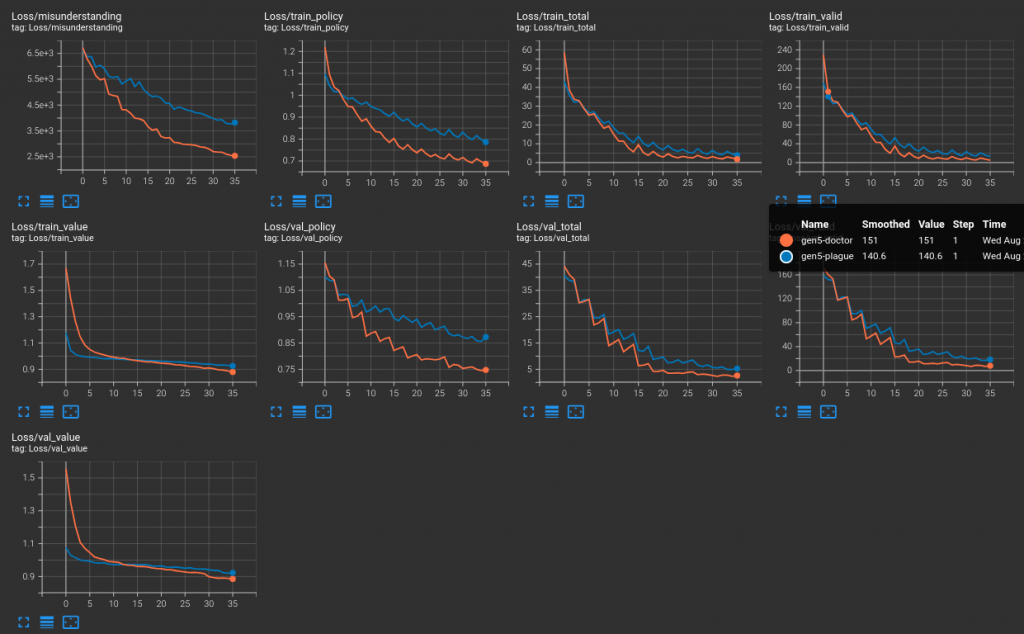
8/24,gen7 其實蠻混亂,當初也不確定到底該做什麼,怎麼做才對(Well,也不是說現在就真比較清楚,但至少,打贏 random 不再是遙遠的目標?)。這個階段改動很多東西,但不值一提。gen8 亦然。但這個區間左右,實作了讀譜程式,也在 git history 之外安插了一些 print 大法除錯,最終有發現一個抵達模擬終局時的價值錯誤問題,也將之修正。這已經是 8/29 的事情了。此間還有一組大型修正,介紹其中的一個錯進錯出的 bug
為了確保蒙地卡羅狀態機的運行,我插了一兩個中斷語句在關鍵處。其中一個是
else:
# [RL]
# Run the child node who has the maximum PUCT
max_action_puct = float('-inf'); # 這是初始化
assert self.current_node.child_nodes.keys() != list(self.candidate), "Why???" # <== 這是這個小節的主角
# 以下走過所有子節點,計算它們的 puct 值並取代 `max_action_puct`
這個中斷句之所以可以維護整個狀態機的穩定,是因為我在遞移模擬著手與實際著手的時候,有時會複用既存的子節點以及它長出來的樹,畢竟在先前它只是個子節點的時候,也可能探索了一些它的子節點,而儲存那些資訊下來不需要耗費太多空間,相較之下,重新計算它們會很花時間。所以在擷取的片段中,我們可以比較,當前節點的子節點一字排開,是否恰好等於當前節點的盤面狀態下,可以選擇的著點。如果不是的話,輸出這個無語問蒼天的 Why??。
但問題是,這兩個,型別根本不一樣啊!所以通常是恆真的。所以後來改成
assert len(self.current_node.child_nodes.keys()) == len(list(self.candidate)), "Why???"
雖然沒有完全檢查到內容,但至少可以把關一點點吧。
以這個 patch 為首,我設想節省了策略與合法性兩組輸出,對於訓練時間與推論時間的節省。但其實這兩組相較於整個網路來說佔比非常小,所以也沒有節省到時間。更嚴重的是,少了策略的學習,只靠蒙地卡羅隨機探索似乎沒什麼效果。
所以我預期會再 revert 掉那些 patch,恢復三組輸出的作法。然後預計今天把大部份的網頁對弈程式碼寫完。
可以期待真人可以透過網頁對弈了嗎 
QQ... 捨命陪君子... 理論上有可能...
如果之後 api 開好,我們這邊的人也可以做一份前端去接 

